
在人工智慧 (AI) 推理的時代,訓練更聰明、更強大的模型對於擴展智慧而言至關重要。為了滿足這個新時代的強大效能需求,需要在 GPU 、 CPU 、網路介面卡 (NIC) 、網路的垂直擴展 (scale-up) 和水平擴展 (scale-out) 、系統架構,以及大量的軟體和演算法等方面取得突破性進展。
NVIDIA 在 MLPerf Training v5.1 中橫掃全部七項測試,於大型語言模型 (LLM) 、圖像生成、推薦系統、電腦視覺和圖像神經網路等領域均創下最快的訓練速度。 MLPerf Training v5.1 為持續多年舉辦的 AI 訓練效能業界基準測試中最新一輪。
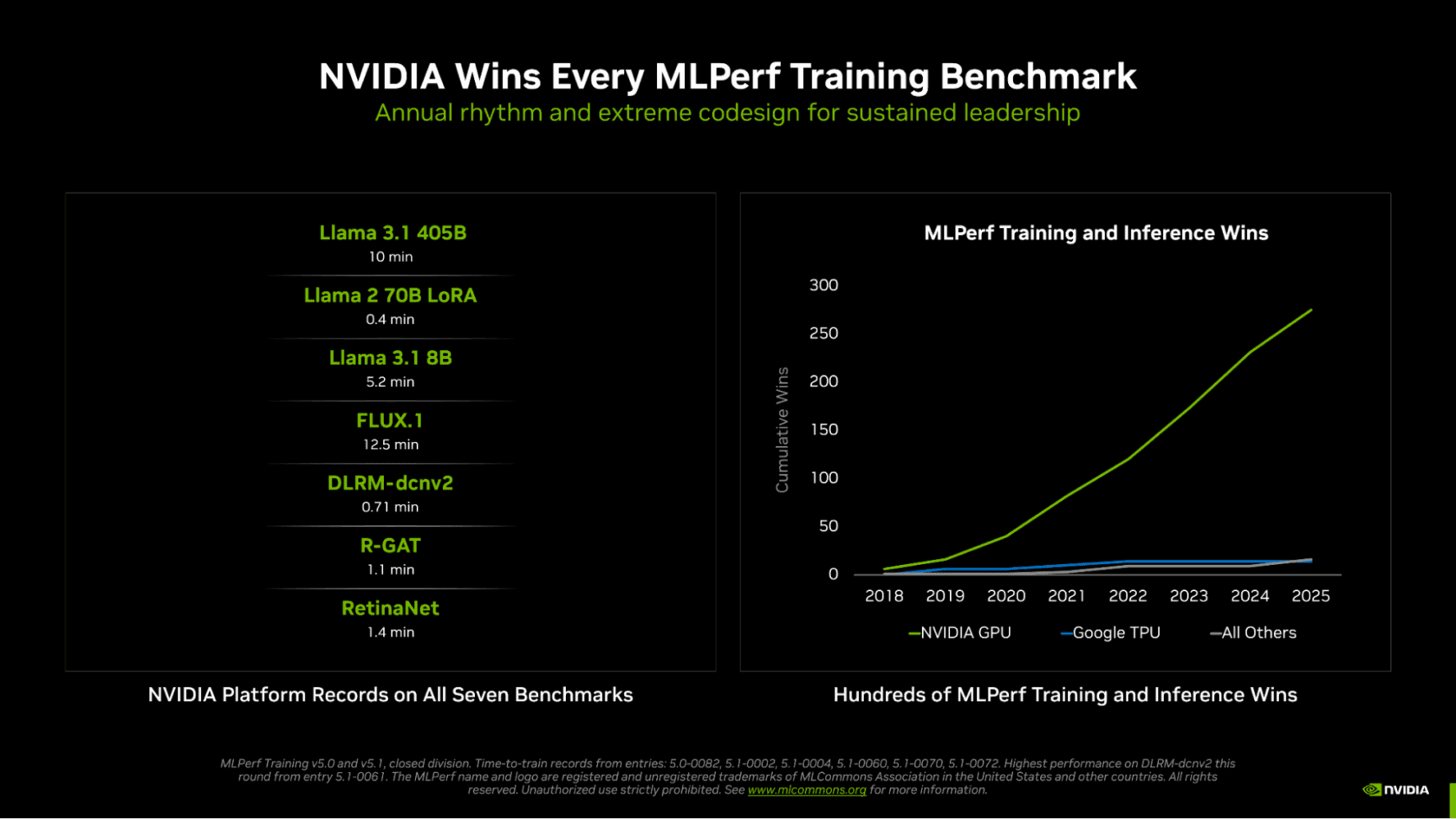
NVIDIA 亦是唯一在所有測試項目中都提交結果的平台,彰顯 NVIDIA GPU 強大的可程式化特性,以及其 CUDA 軟體堆疊的成熟度和通用性。
本文目錄
NVIDIA Blackwell Ultra 再寫佳績
基於 NVIDIA Blackwell Ultra GPU 架構的 GB300 NVL72 機架級系統在本輪 MLPerf Training 測試中首次亮相,在此之前該系統已在最新一輪 MLPerf Inference 測試中創下紀錄。
與上一代 Hopper 架構相比,基於 Blackwell Ultra 的 GB300 NVL72 在相同數量的 GPU 下,Llama 3.1 405B 預訓練的效能提升了 4 倍以上,Llama 2 70B LoRa 微調效能增加了近 5 倍。
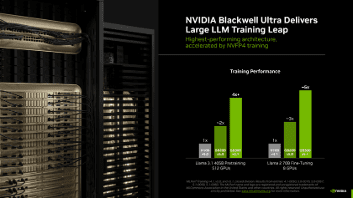
這些效能提升得益於 Blackwell Ultra 的架構躍進,包括具備 15 petaflops NVFP4 AI 運算能力的全新 Tensor Core 、 2 倍的注意力層運算能力,以及 279GB 的 HBM3e 記憶體,同時結合全新的訓練方法,充分釋放該架構龐大的 NVFP4 運算效能。
用於連接多組 GB300 NVL72 系統,且為業界首款端到端 800 Gb/s 垂直擴展網路平台的 NVIDIA Quantum-X800 InfiniBand 平台,也在 MLPerf 測試首度亮相,其橫向擴展網路頻寬較前一代提升 1 倍。
釋放效能:NVFP4 加速大型語言模型訓練
NVIDIA 於本輪取得卓越成果的關鍵,在於採用 NVFP4 精度進行運算,這也是 MLPerf Training 歷史上的首次創舉。
提升運算效能的其中一個方法,是打造能以較少位元表示資料並進行運算的架構,並以更快的速度執行這些計算。然而,精度降低意味著每次計算可用的資訊量減少,因此在訓練過程中使用低精度計算需要謹慎設計決策,以確保結果的準確性。
NVIDIA 團隊在每一層技術堆疊都進行了創新,以將 FP4 精度應用於大型語言模型訓練。 NVIDIA Blackwell GPU 可執行 FP4 計算,包括 NVIDIA 設計的 NVFP4 格式及其他 FP4 變體,計算速度是 FP8 的兩倍。 Blackwell Ultra 更將此效能提升至 3 倍,使 GPU 得以提供更強大的 AI 運算效能。
NVIDIA 是迄今為止唯一一個在滿足基準測試嚴格精度要求的同時,使用 FP4 精度進行計算並提交 MLPerf 訓練結果的平台。
NVIDIA Blackwell 突破擴展效能
NVIDIA 憑藉逾 5,000 顆 Blackwell GPU 的高效協同運作,在 Llama 3.1 405B 測試中創下了僅需 10 分鐘訓練時間的全新紀錄。這項成績較上一輪基於 Blackwell 的最佳成績高出 2.7 倍,歸功於 GPU 數量增加至原先 2 倍以上的高效擴展,以及採用 NVFP4 精度大幅提升每顆 Blackwell GPU 的有效效能。
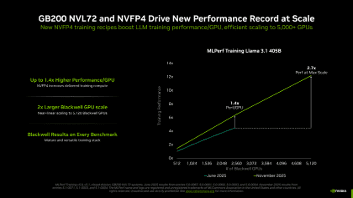
為說明每顆 GPU 的效能提升幅度,NVIDIA 本輪提交採用 2,560 顆 Blackwell GPU 的測試結果,訓練耗時縮短至 18.79 分鐘,較上一輪採用 2,496 顆 GPU 的提交方案快上 45% 。
全新基準測試,全新效能紀錄
NVIDIA 在本輪新增的兩項基準測試中同樣創下效能紀錄,包括 Llama 3.1 8B 與 FLUX.1 。
Llama 3.1 8B 是一款精巧卻功能強大的大型語言模型,取代了長期運行的 BERT-large 模型,為基準測試套件增添更現代化、更小的大型語言模型。 NVIDIA 使用多達 512 顆 Blackwell Ultra GPU 提交了測試結果,創下僅需 5.2 分鐘即可完成訓練的紀錄。
此外,FLUX.1 是一款先進的圖像生成模型,取代了 Stable Diffusion v2,且只有 NVIDIA 平台提交了該基準測試的結果。 NVIDIA 使用 1,152 個 Blackwell GPU 提交的測試結果,創下將訓練時間縮短至 12.5 分鐘的新紀錄。
NVIDIA 持續保持現有圖像神經網路、目標偵測和推薦系統測試的紀錄。
廣泛且深度的夥伴生態系
NVIDIA 生態系在本輪測試中展現積極參與度,共計 15 個機構提交了令人矚目的成果,其中包括華碩、戴爾科技集團、技鋼科技、 HPE 、 Krai 、 Lambda 、聯想集團、 Nebius 、雲達科技、 Supermicro 、佛羅里達大學、 Verda(原 DataCrunch) 和緯穎。
NVIDIA 以一年為週期持續創新,在預訓練、後訓練及推論階段推動顯著且快速的效能提升,為邁向全新層級的智慧鋪路,加速 AI 普及化。