Nvidia 釋出 NVLM 1.0 大型語言模型,挑戰 OpenAI 和 Google,提供開原碼專案支援,含多模態能力,展示在視覺、文字處理等方面的高效能,並強調其創新架構與開發潛力。
Nvidia 上周以開原碼專案釋出 NVLM 1.0 大型語言模型 (LLM) 家族,挑戰 OpenAI GPT 與 Google 。
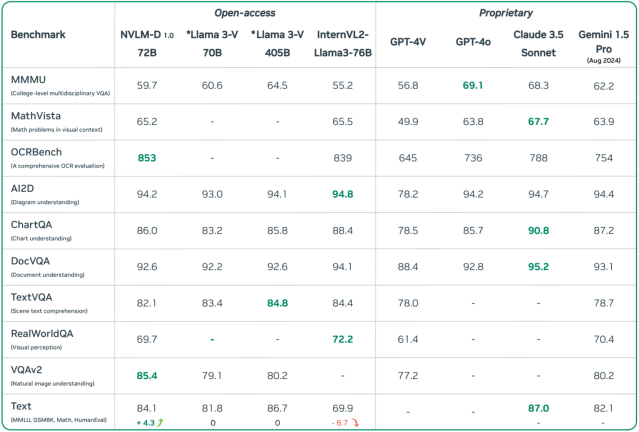
Nvidia 上周釋出模型權重資料,承諾會再釋出訓練程式碼,讓第三方研究人員及開發商用於 AI 專案。 NVLM 1.0 家族最大的是 720 億參數的 NVLM-D-72B,具多模態能力,號稱在複雜視覺與文字處理都有絕佳效能,比起封閉模型(如 GPT-4o)也毫不遜色。

Nvidia 研究人員也展示該模型解讀表情符號、分析圖像與解決數學題的能力。此外,相較於其他模型經過多模態訓練後,純文字任務效能會下降,但 NVLM-D-72B 卻能維持高效能。 Nvidia 指出,在數學題和程式編碼等純文字任務上,該模型平均準確率還提升 4.3% 。
Nvidia 希望藉此加速在 AI 領域上由 OpenAI 、 Google 或 Anthropic 等新創公司獨霸的局面。由於其模型以開原專案釋出,可讓獨立研究人員及小型開發商也能開發 AI 應用。 NVLM 專案也展示了創新架構設計,包括結合不同多模處理技術的混合策略,可促進未來研究方向。當然也可能遭到有心人士濫用、誤用。
Nvidia 的加入必然為 AI 版圖投下震撼彈,這項開原碼專案另一個影響是,當 Nvidia 將 LLM 免費提供後,以 AI 模型營生的公司可能得提升自己的價值才能讓企業用戶買單。
來源:VentureBeat