自今年 1 月 Meta 發表 AV-HuBERT(Audio-Visual Hidden Unit BERT) 語言模型,結合語音和人臉嘴唇動作來理解語音內容,近期 Meta 更推出新的多語言視聽資料庫 (MuAViC),是沿襲 AV-HuBERT 改良版後的新產品。
從這次 Meta 釋出的 MuAViC 訓練 AV-HuBERT 模型的影片就能發現,MuAViC 最大的亮點就是可在吵雜環境下進行語音辨識和翻譯,能利用視覺及聽覺理解語音內容外,還可分析人類唇語提高 AI 對語音內容的理解度。
MuAViC 支援 9 種語言,現已開放原始碼供所有開發人員免費使用
MuAViC 是 Meta 開發的最新語言辨識和翻譯模型,現已擁有 1,200 個小時的轉錄數據,並支援 9 種語言(英語、阿拉伯語、德語、希臘語、西班牙語、法語、義大利語、葡萄牙語及俄語)。 Meta 表示這次釋出的範例影片在 AV-HuBERT 模型的框架下,英語對話的轉錄有使用到 LRS3(一種英語專屬使用的資料集)中的影像資料,再藉由文字配對演算法跟機器翻譯的資料庫配對,然後把配對的樣本跟機器翻譯的資料集,裡面相應的句子比對,確認用字無誤後,做上標籤儲存。
但若沒有經過資料集成功配對樣本誕生出的資料,則會加上一個假翻譯標籤,代表這項結果並不是最精準的版本。
非英語談話的內容,MuAViC 則會重複使用語音翻譯數據集中蒐集的純語音資料、轉錄跟文字來翻譯。為了增加視覺呈現的精準度,系統會把原始錄音的影音軌道,將處理後的影音資料跟語音資料相互對齊,以此產生視聽資料,作為往後非英語談話內容翻譯使用。
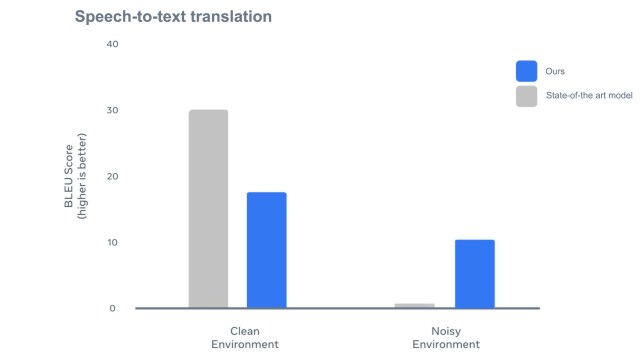
經 Meta 實測,會發現即便在吵雜的背景下,AV-HuBERT 模型再結合 MuAViC 之後,還是可以清楚將語音翻譯成正確的文字,語音辨識不足的地方用唇語便是做補足,數據對比下可驗證與其他翻譯模型相比準確度更高。目前 Meta 已將 MuAViC 放上開源社團 GitHub 供大家免費使用。