Anthropic 在推出 Claude Opus 4.7 約一個半月後,再度發布 Claude Opus 4.8 。新版本加入動態執行代理式工作流程與自主修正能力,使模型能更有效管理與協調多個代理人,處理規模更大的複雜任務。
Claude Opus 4.8 強化代理式工作流程
Claude Opus 4.8 以 Claude Opus 4.7 為基礎進一步強化,價格維持不變。新版本導入動態工作流程 (Dynamic Workflow) 機制,讓 Claude 能在單一執行階段中規劃並執行數百個平行子代理人。系統可於多階段流程中追蹤已完成與待完成步驟,並在回覆使用者前驗證子代理人的輸出結果。
此外,當執行過程發生錯誤或環境異常時,Claude Opus 4.8 可自行調整執行方向並持續完成任務,而非直接回傳錯誤訊息並中止。 Anthropic 表示,這些能力使 Claude Code 搭配 Opus 4.8 後,能夠處理數十萬行程式碼規模的專案,包括啟用、修改或合併程式碼,並可整合既有測試套件進行驗證。目前該功能以研究預覽版形式,提供 Enterprise 、 Teams 與 Max 方案用戶於 Claude Code 中使用。
Fast Mode 與 Effort 控制功能同步推出
在官方公布的基準測試中,Claude Opus 4.8 於多項指標與市場主要模型競爭。在代理式軟體工程測試 SWE-Bench Pro 中,Opus 4.8 獲得 69.2% 的成績,高於 OpenAI GPT-5.5 的 58.6% 以及 Google Gemini 3.1 Pro 的 54.2%,顯示其在大型真實程式庫任務中的規劃與執行能力。
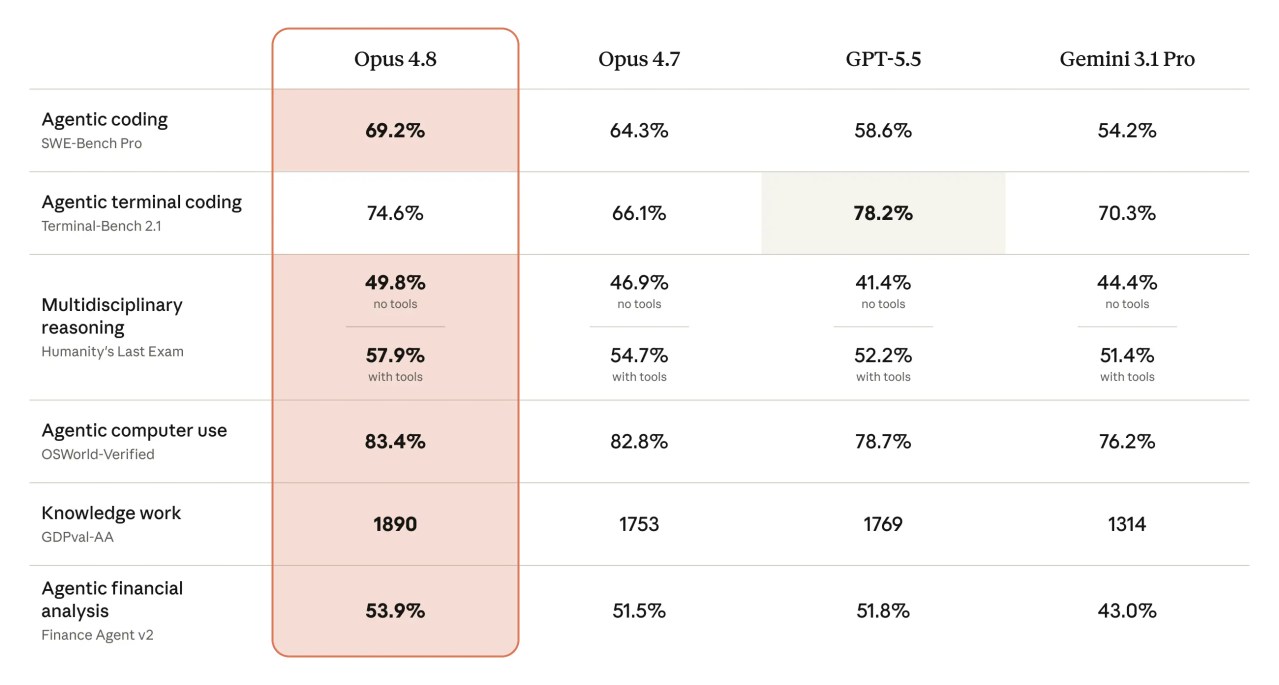
除程式開發任務外,Opus 4.8 在電腦操作與專業知識相關測試也有表現。在瀏覽器代理測試 Online-Mind2Web 中,Opus 4.8 取得 84% 的分數。 Anthropic 指出,在代理式金融分析 (Agentic Financial Analysis) 及法律代理相關基準測試中,Opus 4.8 的表現也優於 GPT-5.5 與 Gemini 3.1 。
除了提升能力表現外,Anthropic 也強調降低模型幻覺與提升誠實度 (Honesty) 。例如在程式碼檢查任務中,Claude Opus 4.8 忽略程式瑕疵的情況較前一版本減少,並會在模型對答案缺乏足夠把握時主動標示不確定性。
Anthropic 同時為 claude.ai 與 Claude 相關協作環境新增 Effort 控制功能,讓使用者調整模型投入的推理程度。提高設定時,Claude 將投入更多推理資源並產生較深入的回應;降低設定則可加快回應速度並減少 Token 消耗。目前所有方案均已提供此功能。此外,當 Claude 拒絕回答特定問題時,也將提供更詳細的拒答原因說明。
另一項更新則是研究預覽版的快速模式(Fast Mode)。透過設定「Speed: Fast」,Anthropic 表示其輸出 Token 生成速度最高可達 Claude Opus 4.7 的 2.5 倍,而價格則為原本的三分之一。
來源: Anthropic