最好的留在最後,在聖誕消息 12 連發的最後一天,OpenAI 執行長 Sam Altman 宣佈最新具推理能力的 AI 模型最新版 OpenAI o3 、 o3 mini 。
o3 系列是今年九月推出的 o1 的升級版。目前 o3 處於安全測試階段,僅供第三方安全研究登記測試以及 OpenAI 和專家團隊進行紅隊演練測試。
OpenAI 表示,o3 模型使用「私有思維鏈 (private chain of thought)」,模型在回應用戶前會先停下來檢視內部對話,再好好計畫如何回應,也可以稱為「模擬推理」(simulated reasoning, SR),是一種超越基本 LLM 能力的 AI 模型。
據《Information》報導,新模型不叫 o2 是為了避免和英國電信業者 O2 鬧雙胞。 Altman 上周也坦承,因為 OpenAI 向來對品牌命名不太擅長,因而要叫 o3 。
OpenAI 指出,o3 在 2019 年以來未曾被擊敗的視覺推理標竿測試 ARC-AGI 中,締造了破紀錄成績。在低運算任務中,o3 獲得 75.7%,而在高運算任務則獲得 87.5% 的高分。如果到 85% 就等同人類的能力。
OpenAI 還指出,在 2024 年美國數學邀請測驗賽中,o3 得分 96.7%,僅僅錯一題。此外,它在 GPQA Diamond 測試中拿了 87.7%,這項測試包含生物、物理和化學題。最後,在 EpochAI 的尖端數學 (Frontier Math) 標竿測試中,o3 解決了 25.2%,其他模型都沒能超越 2% 。
ARC 獎項基金會主席說,看到測驗結果,使他自覺需要改變對 AI 和 AI 能力的看法。
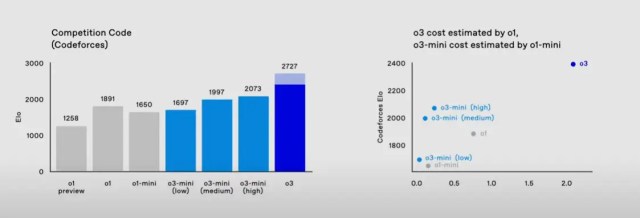
OpenAI 上周也公佈了 o3-mini 模型,它是由 o3 蒸餾縮減而成.具備適應性思考時間功能,提供低、中、高運算速度,設定的運算量愈高,測試成績愈好。 OpenAI o3-mini 的 Codeforces 標竿測試成績比 o1 還好。
模擬推理為新興技術
OpenAI o3 也加入了其他開發自有 SR 模型的廠商行列。 Google 上周宣佈了 Gemini 2.0 Flash Thinking Experimental 實驗模型。 11 月,DeepSeek 推出了 DeepSeek-R1,阿里巴巴的通義千問 (Qwen) 團隊則預覽了 QwQ 。
這些新 AI 模型是以傳統 LLM 為基礎開發,但更為創新:它們經過微調後能產生一連串反覆思考的過程,因而能自己思考結果與模擬推理,推論時以近乎暴力方式擴充,而不需在模型訓練時自我改進。
OpenAI 讓 o3 系列通過安全測試後,預計 2025 年一月底先推出 o3-mini,再推出 o3 模型。
來源:Ars Technica