在眾家競爭者相繼公佈小語言模型之際,Meta 昨 (23) 日公佈經典大語言模型 Llama 3.1 家族,包括參數量達 4,050 億的版本,Llama 3.1 並在 IBM 、 NVIDIA 、 AWS 等多個雲端平台同步上線。美國 WhatsApp 及 Meta AI 用戶可搶先試用 405B 版本。
Llama 3.1 是 4 月公佈的 Llama 3 的新版,當時只提供 80 億 (8B) 及 700 億 (70B) 版本,今天 Meta 也公佈了 Llama 3.1 8B 及 70B 模型。 Llama 3.1 的 context length 加大到 128K,支援 8 種語言。
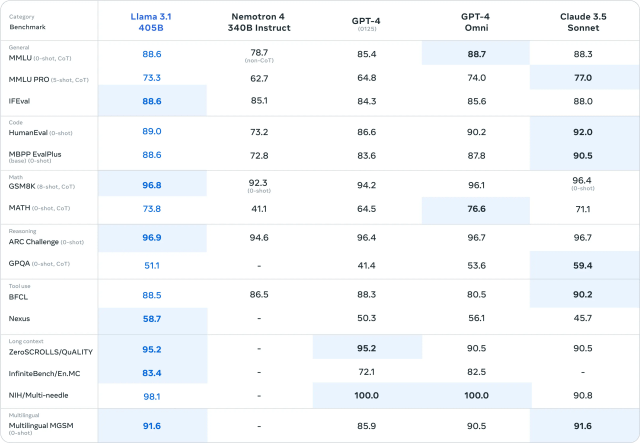
Meta 指出最新 Llama 3.1 405B 不僅是該公司最大模型,也相信是全球最大且功能最強的開原語言模型。它是以超過 15 兆個 token,在 1.6 萬顆 H100 GPU 環境中訓練而成。訓練策略上,團隊選擇標準的 decoder-only transformer 模型架構小幅修改,而非使用專家混合 (mixture-of-experts) 模型以擴大訓練穩定性。此外,研究人員也使用疊代後訓練,每一回都使用監督微調及直接偏好最佳化 (direct preference optimization, DPO),使其得以建立最高品質的合成資料,一次一次提升模型效能。 Meta 號稱效能超越 Open AI GPT-4/GPT-4o 、 Anthropic 的 Claude 3.5 Sonnet 。
研究團隊也進行模型蒸餾,由模型精度由 16-bit(BF16) 降至 8-bit(FB8) 。透過模型蒸餾,開發人員得以將資訊從 Llama 傳授到小型模型上,如 Llama 3.1 70B 和 8B 。
為確保模型安全,Meta 也加入安全工具,包括 Llama Guard 3 、 Prompt Guard 和 CyberSecEval 3 。 Llama Guard 3 是一種輸入、輸入的多語仲裁工具,Prompt Guard 可防範指令注入攻擊,CyberSecEval 3 則是協助 AI 模型和產品開發商了解和降低 AI 網路安全風險的評估工具。
搭配 Llama 3.1 推出,Meta 也變更了授權,方便開發人員使用 Llama 3.1 模型來改進其他模型。新授權限允許模型蒸餾 (distillation) 及建立合成資料。現在開發人員和研究社群已可在 llama.meta.com 和 Hugging Face 上下載。
在一般用戶方面,現在 Llama 3.1 405B 只在美國開放 WhatsApp 及 meta.ai 用戶試用。
Llama 3.1 家族現在已在 25 個雲端平台,包括 AWS 、 IBM Watsonx 、 NVIDIA 、 Databricks 、 Cloudflare 、 Groq 、 Dell 、 Azure 、 Google Cloud 及 Snowflake 等上線。
Meta AI
MetaAI 昨天也宣佈 Meta AI 的 AI Chat,即將在歐盟及英國上線。 IG 中的 Meta AI 也增加 2 項新 AI 功能:Imaging Yourself 可以用戶相片為基礎,讓 MetaAI 製作頭像,Imagine Edit 則讓 MetaAI 編輯物件。另外,Meta 新增 7 種支援語言,包括法、德、義、西、葡、北印度語 (Hindi) 及天城文(Hindi-Romanized Script,印度和尼泊爾地區使用的文字)。 Meta AI 並且擴大上線地區,包括南美洲的阿根廷、智利、哥倫比亞、厄瓜多、墨西哥、祕魯、及非洲的喀麥隆。預期會逐步開放其他地區使用。 Meta 稍早提過,計畫不提供多模 AI 的歐盟,也會推出新版純文字語言模型。
來源:Meta