Meta 的 AI 研究人員最近公佈新 AI 模型 MobileLLM 的研究,是為智慧型手機和其他運算資源有限的裝置而設計的高效語言模型,同時挑戰了既有模型參數愈多愈準確的假設。

這項研究的研究團隊由 Meta Reality Labs 、 PyTorch 和 Meta AI Research (FAIR) 部門組成,他們想實驗參數量小於 10 億的模型最佳化方法。 10 億是 GPT-4 等大模型參數的零頭而已,外界預估 GPT-4 參數量超過一兆。
Meta AI 首席科學家 Yann LeCun 說明這項研究重點包括:
- 突顯模型深度比廣度重要
- 實作內嵌 (embedding) 共享與群組查詢注意力 (grouped-query attention, GQA)
- 利用創新的立即區塊導向權重共享 (immediate block-wise weight-sharing) 技術。
這些設計元素讓該公司 MobileLLM 1.25 億及 3.5 億版本模型在執行準確率上,比同樣大小的其他(稱為 state of the art, SOTA)模型平圴均值高出 2.7% 和 4.3% 。雖然看似不多,但對 LLM 而說已是相當大的改進了。
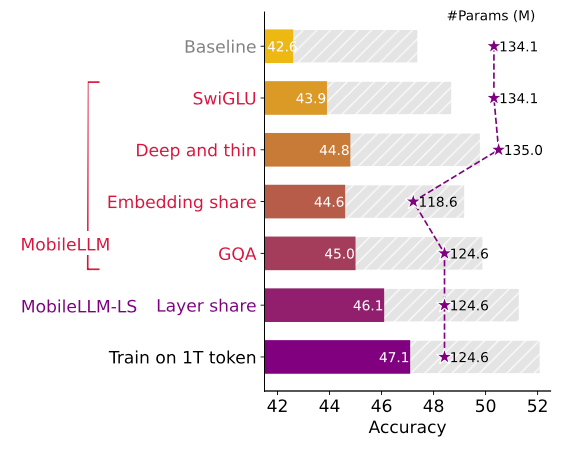
此外 3.5 億版本 MobileLLM 在特定 API 呼叫的準確率和 LLaMA-2 7B(70 億參數)不相上下,這顯示對某些應用而言,較小型的模型不但使用較少運算資源,準確性也不會大打折扣。
MobileLLM 的開發也正呼應了企業想要高效 AI 模型的潮流。超大型模型發展趨緩,相反地,研究人員開始探索小型、專門化的模型設計,稱為小型語言模型 (small language model, SLM) 。 MobileLLM 目前尚未開放大眾使用,但 Meta 已將預訓練程式開放原始碼,讓其他研究人員自建模型,或是開發跑在行動裝置上的 AI 應用。
在裝置端 AI 模型方面,Google 已經推出了 Gemma 1 、 2,蘋果也公佈了 OpenELM,其中 OpenELM 也有二個版本小於 10 億(OpenELM 270M/450M)。
來源:VentureBeat