微軟本周說明它建立了一個行星規模等級的 AI 任務分散式排程服務,稱為 Singularity(奇點),每台伺服器可能包含 10 萬顆 GPU 。
根據微軟 Azure 研究部門一份由 26 名員工共同撰寫的論文,Singularity 原本設計目的是藉由提高深度學習用量以協助成本控管。
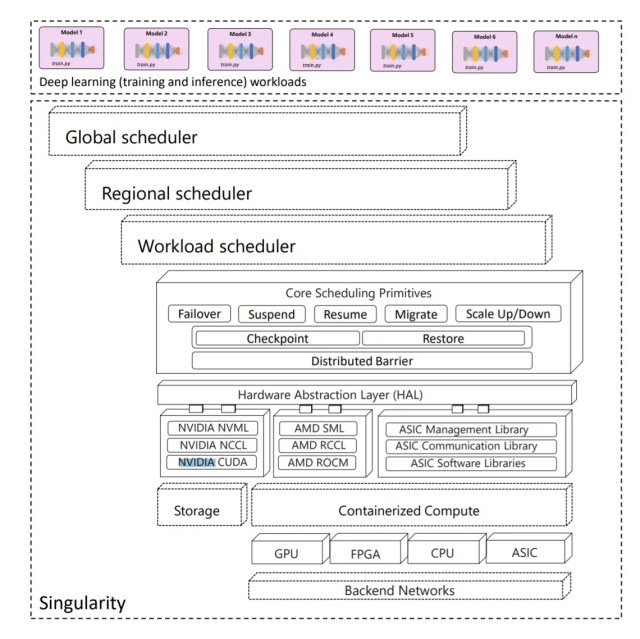
微軟指出,Singularity 的原理是運用「能感知工作任務的排程器,結合一整組 AI 加速器(例如 GPU 或 FPGA)預先動作並且彈性擴充深度學習應用,以推高使用率而且不影響效能或精確性。」
根據論文,Singularity 架構在搭載 Xeon Platinum 8168 CPU 的 Nvidia DGX-2 伺服器上,每台伺服器有 2 socket,每 socket 各 20 核、 8 顆 V100 Model GPU 、 692GB RAM 及以 InfiniBand 互聯。 Singularity 叢集包含數十萬顆 GPU 、 FPGA,可能還有其他加速器。然後這種伺服器微軟可能少說有幾萬台。
微軟特別強調 Singularity 的擴充技術和排程器,表示這是 Singularity 節省成本及提升穩定性的核心關鍵。
它的軟體會把運行任務和加速器資源切分開來,意謂運行任務可以自由擴充或縮減。使用者只要變更 worker 對應的硬體台數,不論實體跑的硬體有幾台,執行任務的 worker 機器數量都能維持不變。
微軟解釋這要歸功於一種名為複寫剪接 (replica splicing) 的新技術,可在同一台裝置上切出多台 worker,幾乎不影響效能,讓每台 worker 能善用實體裝置的所有記憶體。
這需要有一台「裝置代理伺服器」(device proxy),它有自己的定址空間,和實體加速器裝置呈 1:1 對應。當一台任務 worker 啟動裝置 API 時,API 連線會被攔截,而將共享記憶體送到跑在另一個定址空間上的裝置代理伺服器行程,這個行程又與原有 worker 行程的生命周期不同步。這就能排定更多任務,而且更有效率,讓數千台伺服器得以投入服務,也能彈性擴充、縮減而不影響營運。
簡而言之,Singularity 使深度學習任務的排程有了重大突破,將彈性擴充及 always-on 等少數人能享有的功能帶到主流市場,有了 always-on 功能,排程器就能實現更高的 SLA 。
Singularity 讓人一瞥 Azure 雲 AI 任務管理的能力水準,只可惜論文並未說明微軟會將自己的技術公開或商品化。
來源:The Register